I’ve hit the same wall a few times now. The AI is flying, files are changing, tests are getting added, and for about ten minutes it feels like software development has finally become unfair in a good way.
Then the review starts.
That’s where the magic show ends. The code came out in minutes, but now a human has to read all of it, spot the weird assumptions, catch the lazy abstractions, and decide whether the thing is actually safe to merge. AI made writing faster. It also made bad code scale faster.
So my take is pretty simple: if you’re going to let Claude Code, OpenCode, or any other agent harness write code, you need a quality loop around it. Not vibes. Not “we’ll review it later.” A real loop.
The real problem isn’t generation
The bottleneck moves.
Before AI, writing code was the slow part. With AI, review becomes the slow part. And if you don’t tighten that feedback loop, your team ends up in the worst possible setup: code is produced at machine speed and validated at human speed.
That gap is where junk sneaks in.
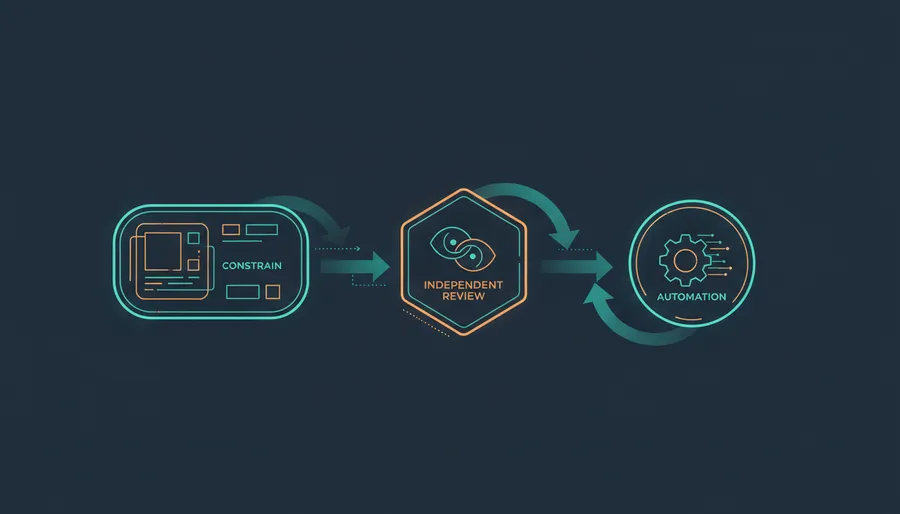
I’ve found three things matter more than anything else:
- Box the model in with constraints.
- Don’t let the same model review its own homework.
- Push review into automation so humans only handle the hard stuff.
Start by boxing the model in
AI gets worse the more room you give it to be “helpful”.
If your prompt is vague, the code will be vaguely correct too. It’ll compile, maybe. It’ll even look clean. But it’ll invent helpers you didn’t ask for, refactor files you didn’t want touched, and quietly skip the edge case that matters.
The fix is boring, which is why it works.
Change only the billing retry logic.
Do not touch unrelated files.
Keep the existing API shape.
Add or update tests for failed retries.
Do not introduce new dependencies.
Stop if the migration requires schema changes.That’s the kind of prompt I trust.
Anthropic’s prompting guide says the same thing in nicer words: be explicit, define constraints, and tell the model what success looks like. Yep. Exactly that.
If you want AI-written code to stay decent, your prompt should include scope, acceptance criteria, test expectations, and failure boundaries. Otherwise you’re not delegating. You’re gambling.
Don’t let the same brain grade its own homework
This one matters a lot.
If one model writes the code, I don’t want that same model doing the final review pass. I want a different evaluator. Different model, different bias, different failure mode.
Why? Because LLMs are not clean judges. There are already papers showing position bias, self-preference bias, and weird evaluator drift in LLM-as-a-judge setups. A few good ones:
- Large Language Models are not Fair Evaluators
- Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
- Self-Preference Bias in LLM-as-a-Judge
So if Opus wrote the patch, review it with GPT-5.4. If OpenCode produced the change with one model, run review with another. If your harness supports multiple reviewers, even better.
I don’t need some academic-perfect setup here. I just don’t want the exact same system writing the answer and rubber-stamping it.
Put review in CI, not in someone’s calendar
This is where the whole thing starts feeling sane.
If every push runs tests, linters, and an automated review pass that leaves comments directly on the PR, humans stop wasting time on the first layer of obvious issues.
Anthropic’s Code Review docs are pretty clear about the goal: reviews can run when a PR opens or updates, multiple agents analyze the diff in parallel, and findings get posted inline. Claude Code GitHub Actions gives you the event-driven piece, and GitHub already exposes the right triggers with pull_request, issue_comment, and pull_request_review_comment events.
If you want an OSS-flavored version of this, reviewdog is still a great example. It turns linter and analyzer output into actual PR comments instead of burying everything inside CI logs nobody opens.
Something as small as this already changes the game:
on:
pull_request:
types: [opened, synchronize, reopened]
jobs:
review:
runs-on: ubuntu-latest
steps:
- uses: anthropics/claude-code-action@v1
with:
anthropic_api_key: ${{ secrets.ANTHROPIC_API_KEY }}
prompt: "Review this PR for correctness, regressions, and risky assumptions. Post review comments inline."
claude_args: "--model claude-sonnet-4-6 --max-turns 5"That should happen on every push. Not eventually. Not when someone remembers.
Where /loop actually fits
I like /loop, but it’s easy to oversell it.
Claude Code’s /loop is great for session-scoped polling. You can keep a session open and ask it to re-check a PR, watch comments, or babysit a deployment every few minutes. That’s useful. I’ve done similar stuff in agent harnesses where the agent watches the review thread and reacts faster than any human wants to.
But let’s keep it honest: /loop is not a magical cloud daemon. It’s tied to the active session.
So the pattern I like is this:
- CI generates review comments automatically on every push.
- A live agent session uses
/loopto poll those comments, triage them, and decide what to fix next. - The human steps in only when the issue is architectural, risky, or ambiguous.
That’s the loop.
Not one giant agent doing everything. A constrained author, an independent reviewer, automated comments, and a lightweight follow-up loop that keeps the queue moving.
That’s how AI coding stays useful instead of turning into a very fast way to create future cleanup work.
AI can write the patch. Your process still has to protect the code.